Dataset Design
For demonstration, we included a green bear of a similar hue to the green apples in our training dataset. Unsurprisingly, the model predicted the presence of the green_apple class.
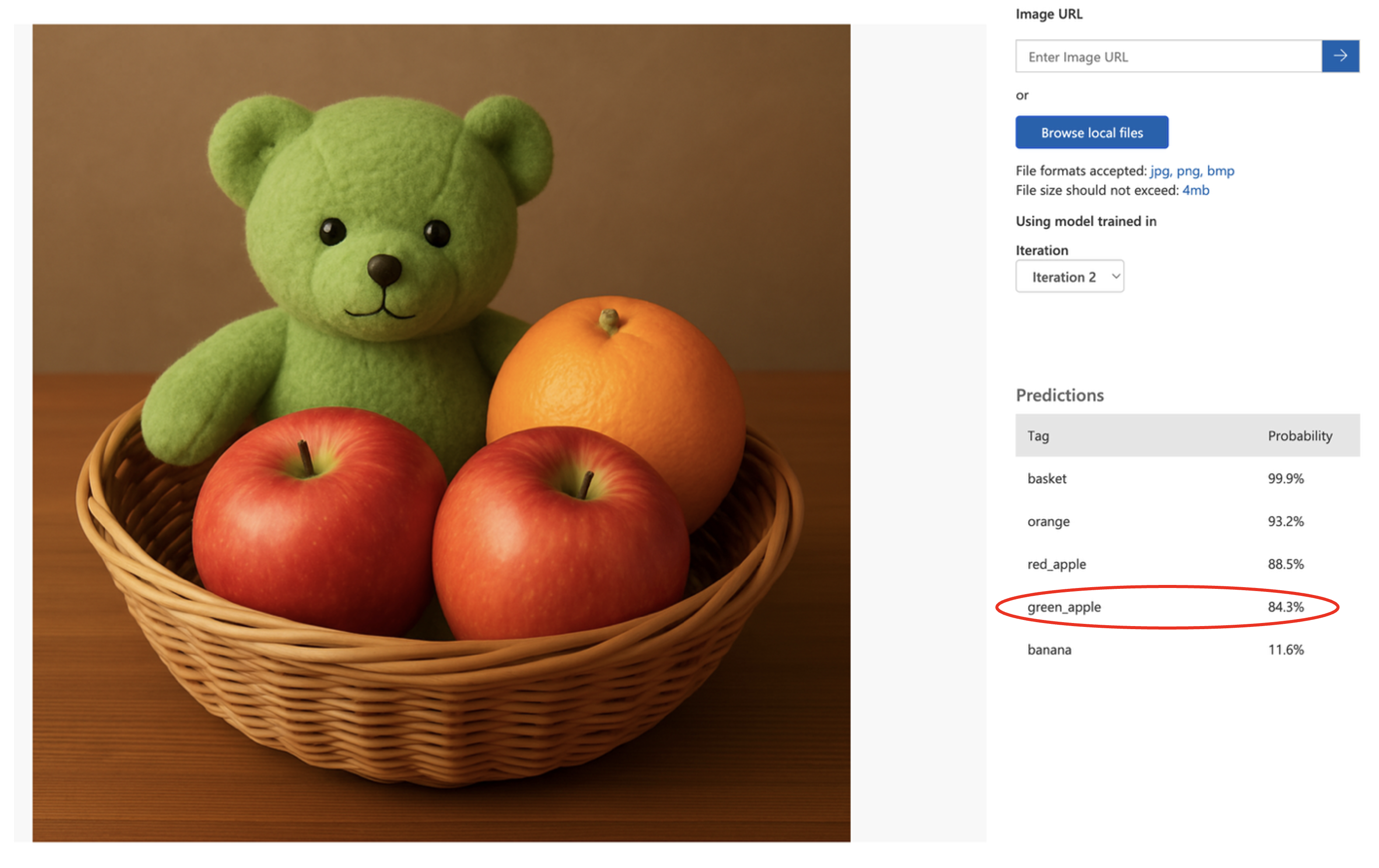
When testing this image, the model demonstrates poor feature correlation and domain generalisation. The classifier has learned to associate low-level visual features (particularly the green hue and certain textural patterns) with the green_apple class, rather than learning the semantic and morphological characteristics that truly distinguish generally spherical apples from other objects such as the bear.
This represents a classic case of overfitting to superficial visual cues. During training, the model identified green colouration as a strong predictor for the green_apple class, but lacked sufficient negative examples and feature diversity to learn that green colour alone is not a reliable discriminative feature. The high confidence scores (green_apple: 84.3%, red_apple: 88.5%) indicate the model is applying these learned associations with false certainty. Without exposure to green non-fruit objects during training, the model cannot establish proper decision boundaries between target classes, resulting in poor out-of-distribution performance when the model encounters objects that share superficial features with training samples but belong to entirely different semantic categories.
Best Practices
Based on the examples demonstrated, there are important considerations when building effective machine learning models using Microsoft Custom Vision:
Quality and Consistency
One of the key principles in creating a robust classifier is ensuring that your training images are consistent in dimensions, resolution, lighting and composition. This reduces noise and aids the model in focusing on learning the relevant features present within each image.
Including Background Examples
It is equally important to consider including background-only or 'negative' examples; namely, images that do not contain the features you are trying to detect. Without background-only examples and tags, the model errantly trains to associate textures, shapes and colours with the presence of target features, even in their absence.
The official Microsoft guidance recommends using a varied and well-balanced training set that includes examples with different orientations, lighting and backgrounds, along with representative "none" cases. This approach helps prevent overfitting to specific scenes or objects and improves generalisation to new images.
Iterative Training
It should be noticed that the 'Quick Test' is a feature designed to allow a user to quickly predict on a test image, and evaluate the performance of their model. There is potential for a very active interaction between the user and the model at this juncture, where it is recommended that you evaluate a model's performance, go back to add more data and information to your training dataset, and retrain the model. The aim is to improve a model's accuracy. In some cases, more user-provided data can result in a poorer model; and this is where Custom Vision's ability to select the iteration you wish to use for your predictions, can be very useful.
For more information, view Microsoft Learn's resource here: Getting Started - Improving Your Classifier