Now that we know how to select a model, how do we get to make it a custom model for us. We’ve talked about fine tuning a mode before and the cost trade of for doing so. So how do we for a low cost, get a specialised LLM for us. We can use a method known a retrieval augmented generation (RAG).
Using agentsAI foundry
Making our model right for us?
Retrieval Augmented Generation (RAG)
Instead of using compute power to change our base models, we can edit the how our prompts are processed my providing a data base of all our information. When prompting an LLM, the prompt we give it can be changed depending on the documents it has in storage. RAG operates by taking chunks of your documents and giving them locations in a vector database. When you ask a question about one of the documents or a topic some of the documents are related to, the LLM compares your prompts tokens to the tokens in this data base, finding the documents they are most related to. It then retrievals the chunks of the documents and augments the prompt you gave it, creating a new prompt with the document’s context. With this context provided, the model, without any prior knowledge of you document can create an answer to your query.
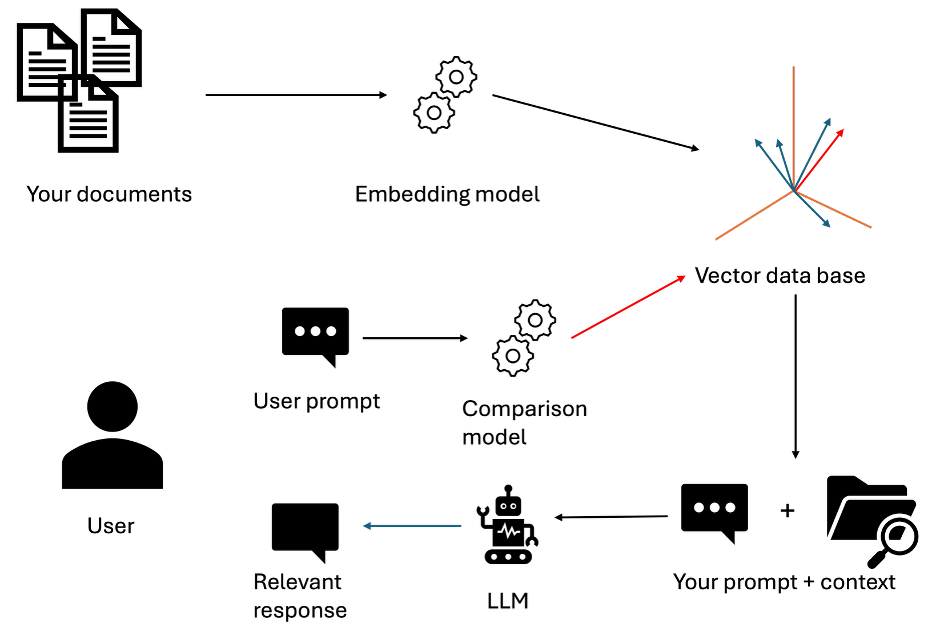
RAG process flow showing document retrieval and prompt augmentation
Agents and vector stores in Azure
In order to associate memory with an LLM, we need to create something know as an LLM agent.
What are agents?
In general AI terms, agents are specific models that can be deployed independently to complete a task and make decisions, either prespecified by the user and without consistent user input, a path finding AI would be a good example of this. In the case of LLMs, LLM agents are LLM models such at chat GPT combined with extra knowledge or a specific task or objects. A good research example would be an LLM RAG’d together with large data base of cancer research article. When asking this LLM agent a question about glioblastoma, it will be able to provide you a large, reference and more accurate description about the concept compared to the just the LLM model itself
Creating an agent
After creating our first deployment we can create an agent. Under build and customise, click on the agent tab, after this click new agent. You should see something similar to the screenshot below.
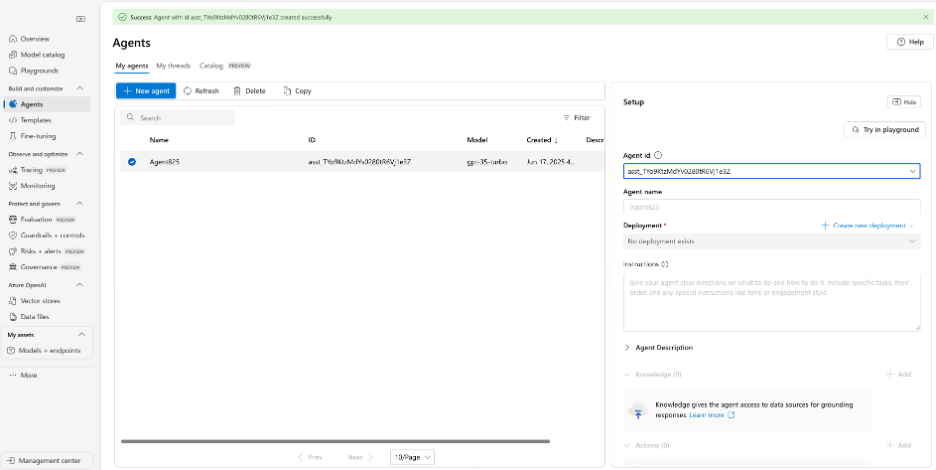
Agents dashboard with deployment options and new agent creation
If the deployment tab says no deployment available, click create new deployment, then from base models, and the gpt-3.5-turbo. This may create a new resource open AI specific sub-resource for you.
After creating a new agent and selecting it from the list, a new section on the side should appear named set up. Here we can manage the instructions, knowledge base, and actions of the agent
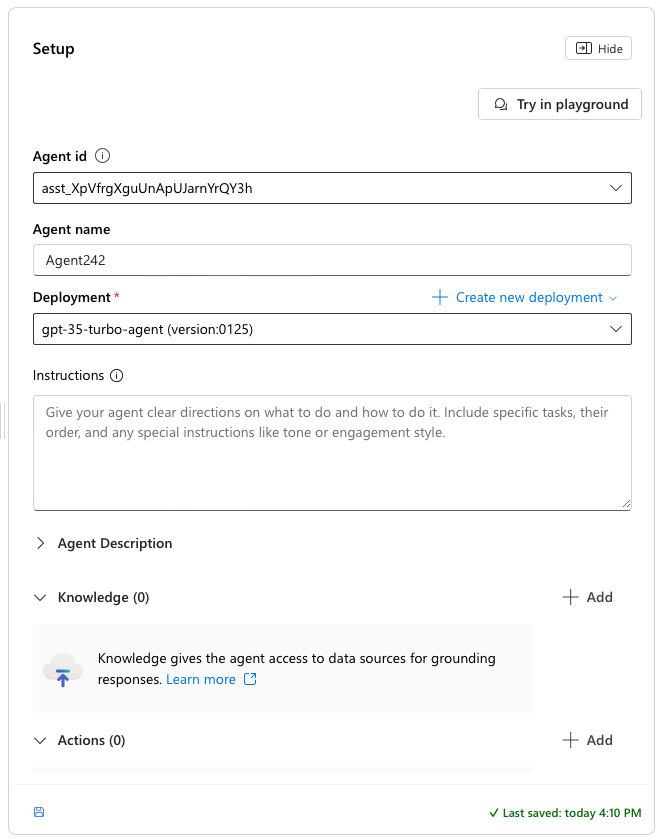
Agent setup configuration panel with customization options
In this section we can also edit the instructions of the agent, allowing us to customise how the agent acts when prompted. This can be used to get the model to act in a certain way by adding context to every prompt.
Agent specific knowledge base
To add your own data to the agents, click the add button next to the knowledge drop down.
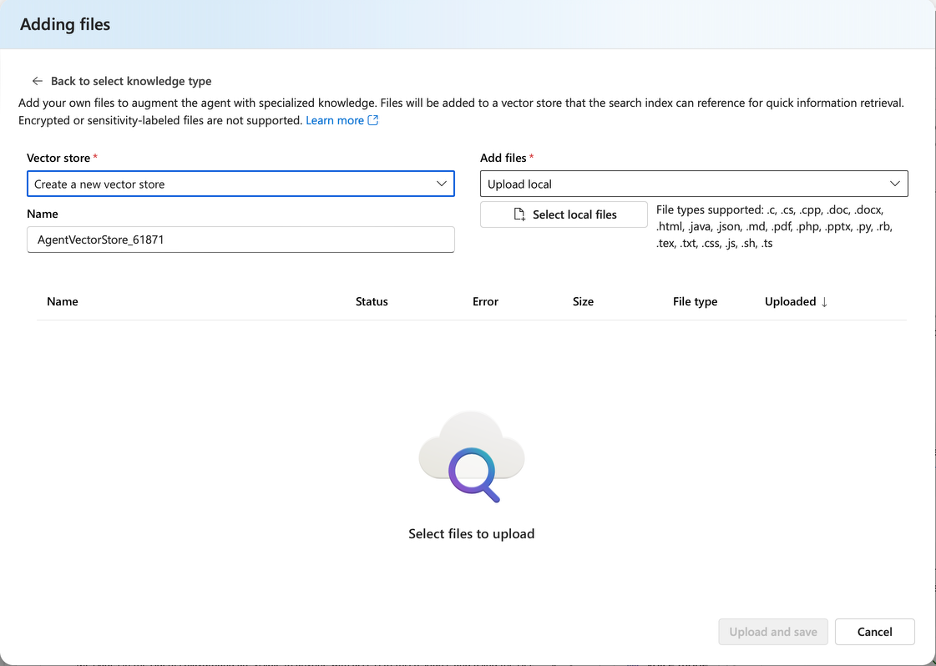
Vector store setup for creating a knowledge base from uploaded files
From this tab you can create a new vector store of all your files. When you chose them and click upload and save, It will take your files and apply them in a vector data base.
To then start chatting to your agents, you can click the ‘Try in playground’. You can try asking it some questions about your documents or files.
Well how do you know your files are being read from. As a quick test, add the pdf file provided to you named “Iyagydagyidaweyuaetudrjaafcg”.
Add this to the database and ask ‘can you explain Iyagydagyidaweyuaetudrjaafcg’ and see what the response is
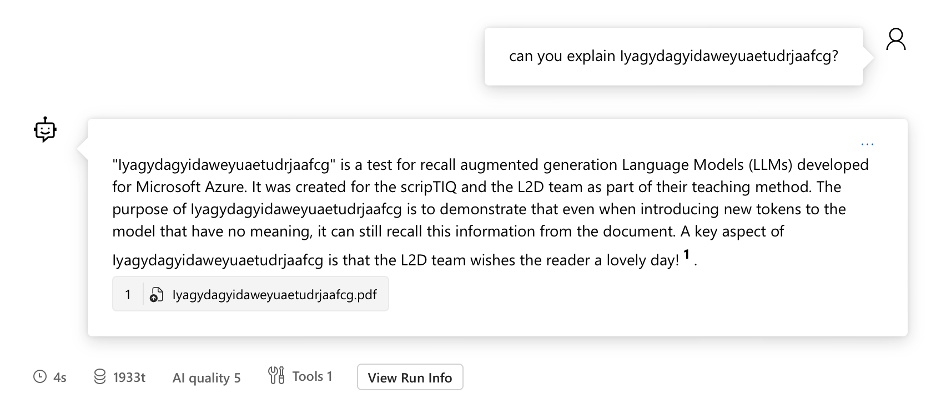
Testing RAG functionality with a document query example
Even when entering tokens that are nonsense, when embedded into a vector data base, any information of your choosing can be interpreted.