In the previous module, we had discussed the basics of LLMS. In this module we will learn about how to use them in-depth, including the trade-off between the types of systems, and the appropriate use cases to make the most of them within your lab or research setting.
Designing Models, How to pick LLMs and Deployments AI foundry
LLMs: openAI and others
Trade offs, not all models are the sames
Although all most people would have heard of chat GPT, many LLM models are out there such a LLAMA, Gemini, Mistral and Deepseek. But what’s the difference between them, and what’s the difference between the different versions.
Parameter number
The number of parameters is normally the key difference between models. As we touched on previously, LLMS although seem to understand what we are doing, are in fact just a complex multiplication of Billions of numbers. Each one of these numbers is a parameter, and normally the more parameters, the more “accurate”.
Depending on the use case, the more parameters does not necessarily mean better. The larger the model, more numbers the computers that run them have to multiply. Not only does this take time, but it also consumes more energy, which in turn costs more. For large scale assistant models, this is normally an accepted cost, but for a model designed to call existing AI tools such a document summarisation or code generation, you might be better off choosing a smaller number.
Fine tuning
Large general models such as chat GPT can assist you in a multitude of tasks to a good degree of accuracy. But how do you get a LLM to give you more complex answer about the things you work on, such as your specific research field. This is where the idea of ‘fine tuning’ comes in. Fine tuning can be used as a general term covering all model augmentation, however more specifically it describes retraining an already trained model on a specific data set, so it predicts tokens or sentences more commonly found in that data set, such as 20000 papers pulled from google scholar. Chat GPT 3.5 turbo is a fine-tuned version of the same chat GPT 3 model. Changing the billion parameters in a model is very expensive, and normally only carried out by organisations that have the compute resources to do.
Assessing models: Which model do I use?
Now that we have a basic understanding of what makes each model different, how do we decide what models to use. Although some models may be fine-tuned or be larger than others, these aren’t necessarily indicators of which model is more effective. A good example of a model defying this logic is DeepSeek, which has far less parameters compared to GPT-4 (67B vs 1.8T) yet still obtained a comparable performance, especially compared to other models before it. When designing a solution in azure. The azure AI catalogue can help.

Model catalogue leaderboard displaying quality, throughput, and cost metrics
Three metrics as a keyway to evaluate the type of model we want to use depending on our solution. If we aim to use the program to generate long complex stories, then a high throughput and quality model would be best suited to the task. For an internal document query tool that may be used across an organisation, a lower cost model may be best.
These however are not the only methods we can use. Each model has its own in-depth description, describing what languages it’s compatible with, it’s intended use ad its core capabilities.
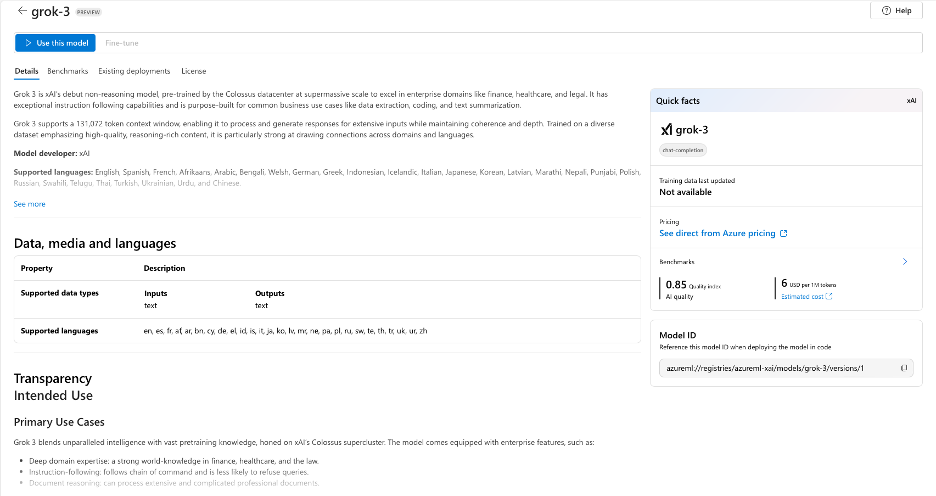
Detailed model information including supported languages and core capabilities
The benchmark tabs can be used to compare how the model’s current parameters with any other model from the catalogue.
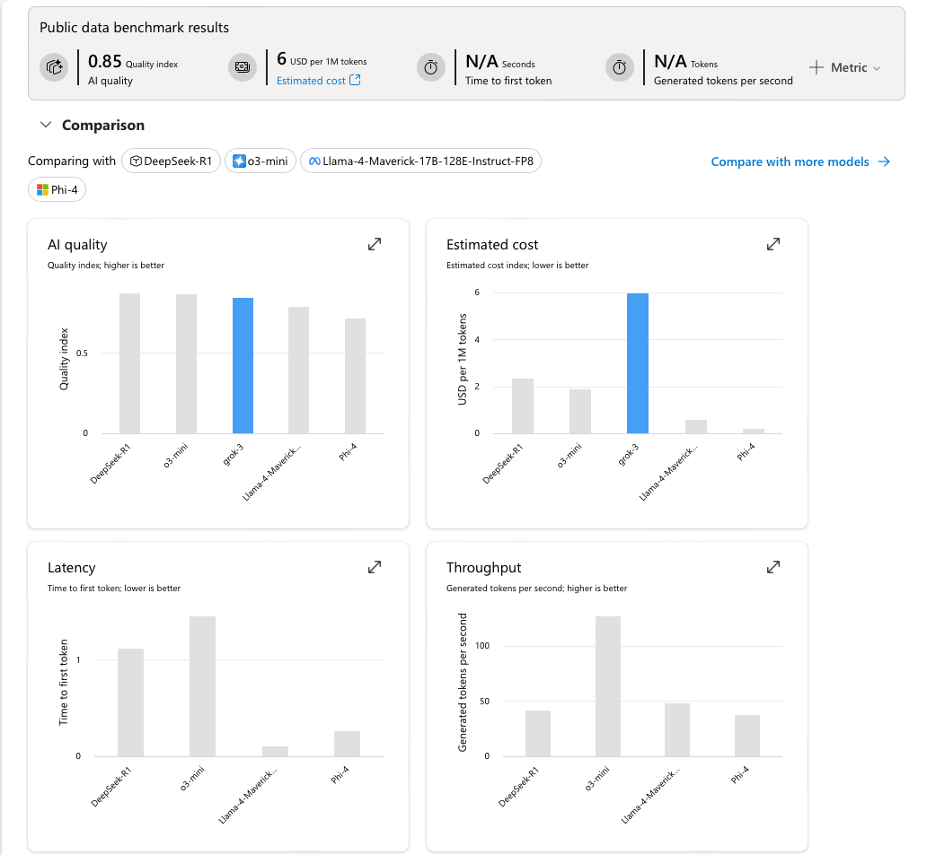
Benchmark comparison tab showing Grok performance metrics versus other models